
我们提供安全,免费的手游软件下载!
作者:vivo 互联网大数据团队- Wu Yonggang、Li Xiong
本文是vivo互联网大数据团队《用户行为分析模型实践》系列文章第4篇 -留存分析模型。
本文详细介绍了留存分析模型的概念及基本原理,并阐述了其在产品中具体实现。针对在实际使用过程问题,探索了基于ClickHouse留存分析模型实践方案。
根据CNNIC的统计数据显示,中国互联网用户已达10.79亿人,互联网普及率达到79.4%。互联网虽然仍然在快速增长,但是用户规模逐渐饱和,互联网事实上已经进入了存量用户时代,整体的流量竞争也越来越激烈,用户的留存的重要性也越来越高于拉新。因此,如何识别忠实用户,了解目标用户群的留存表现?如何分析用户流失情况,优化产品?如何分析目标用户是否完成了期望的行为等等就是我们数据分析的重要课题,而留存分析模型就是我们解决这些问题的重要工具。
留存分析模型主要用于分析触发了起始事件的用户在后续时间周期内触发了后续事件(即回访事件)的比率,该模型可以较好的反映出用户的忠实度或者说是用户的粘性。对于留存分析模型有几个重要的概念要了解:
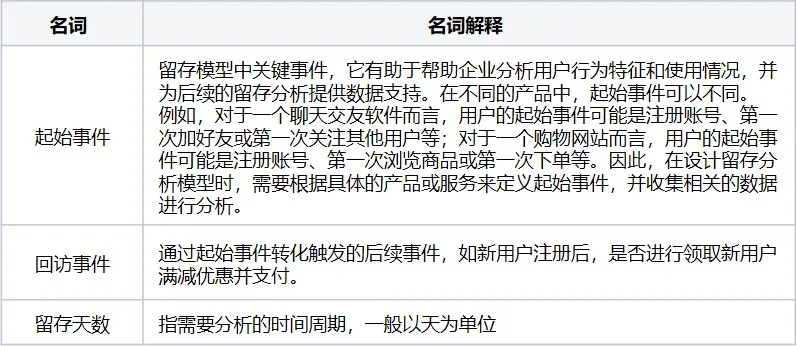
留存分析一般需要指定起始事件和回访事件,但起始事件和回访事件可以相同,也可以不同:
1、起始事件、回访事件可以选择 相同 事件,这种可以很直观地看出触发事件的忠实用户量。
例如:在签到过程中,起始事件为签到成功,回访事件也是签到成功,在一段时间内,连续触发该事件的用户数量即可为忠实用户量。
2、起始事件、回访事件可以选 不同 事件,这种就是比较正常流程下的用户留存数据。
例如:在某个活动中,从下单到成功支付的场景内,起始事件为下单,回访事件为支付成功,这种在一段时间内,触发这两个事件的同一用户为指定流程下的用户留存数据。
留存率作为一个产品的核心指标之一,我们提升产品力,改善使用体验,分析目标用户很大程度上也是为了提升这个指标。比如,我们可以通过计算N日的留存率,来评估某个迭代是否是正向的。如图1所示,某应用优化了首页布局,推出了新版本A,就可以联同旧版本B,分别计算每日的用户留存率,它一般会组成一个衰减的留存曲线。曲线衰减的越慢,说明我们的留存率越高,也就能体现我们首页的修改是有正向的效果的。当然有时留存的提升可能只有百分之零点几,但是在一个很大的用户基数的前提下,也可能产生一些质变的效果。我们也可以将特定的人群圈定为用户组,针对不同的用户组进行留存分析,挖掘更加忠实的用户群体。
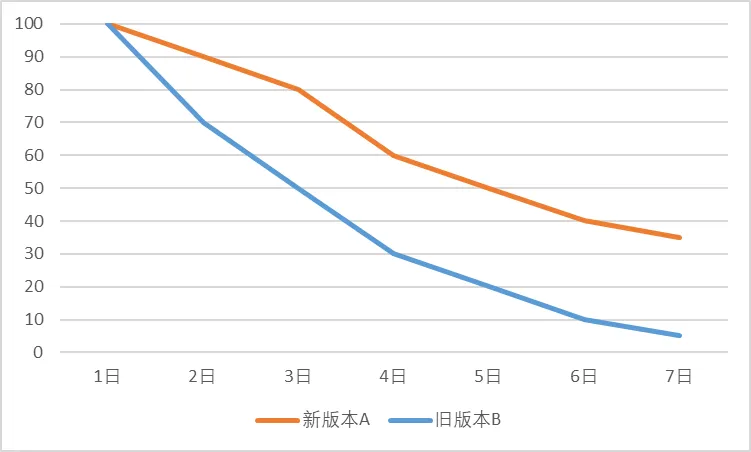
图1 新版本A与旧版本B的留存对比
了解了上面的关于留存模型的基本概念,我们看一下如何创建一个留存。
起始事件:打开浏览器。
回访事件:退出浏览器。
设置一个留存天数为3天。
这里的时间区间概念是指,你需要查看的日期区间,例如选择时间区间为2023-01-06~2023-01-08,则是只计算2023-01-06到2023-01-08这3天,每天的当日留存,第1日留存,第2日留存,第3日留存。
起始用户数 = 计算日期触发起始事件用户数。
当日留存用户数 = 当日触发回访事件的用户与当日触发起始事件用户交集。
第1日留存用户数 = 次日触发回访事件的用户与计算日期触发起始事件用户交集。
第2日留存用户数 = 2日后触发回访事件的用户与计算日期触发起始事件用户交集。
第3日留存用户数 = 3日后触发回访事件的用户与计算日期触发起始事件用户交集。
当日留存率 = 当日留存用户数/起始用户数*100%。
第1日留存率 = 第1日留存用户数/起始用户数*100%。
第2日留存率 = 第2日留存用户数/起始用户数*100%。
第3日留存率 = 第3日留存用户数/起始用户数*100%。
用户留存数表(即表1)表示起始事件为“打开浏览器”、回访事件为“退出浏览器”时,对应2023-01-06~2023-01-09每天的近3天的留存用户数据。
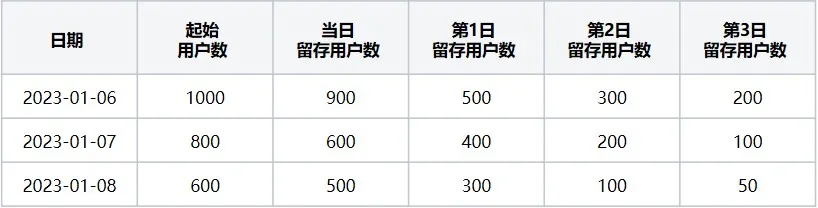
表1 用户留存数表
用户留存率表(即表2)表示 起始事件为“打开浏览器”、回访事件为“退出浏览器”时,对应2023-01-06~2023-01-08每天的近3天的留存用户占比数据。
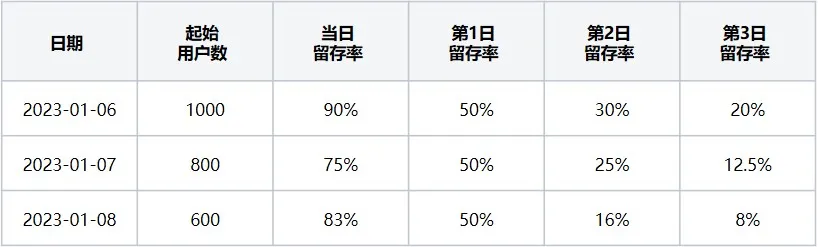
表2 用户留存率表
以表1中2023-01-06日的数据为例,1月6日起始用户数1000:是指触发起始事件“打开浏览器”的用户数;当日留存用户数900:是指在触发起始事件用户中当日又触发回访事件为“退出浏览器“的用户人数;
第1日留存用户数500:是指1月7日触发回访事件且与1月6日中触发起始事件的交集用户数;第2日留存用户数300:是指1月8日触发回访事件且与1月6日中触发起始事件的交集用户数300,以此类推到第3日,此时计算出来的2023-01-06这一天的3天的留存数据!
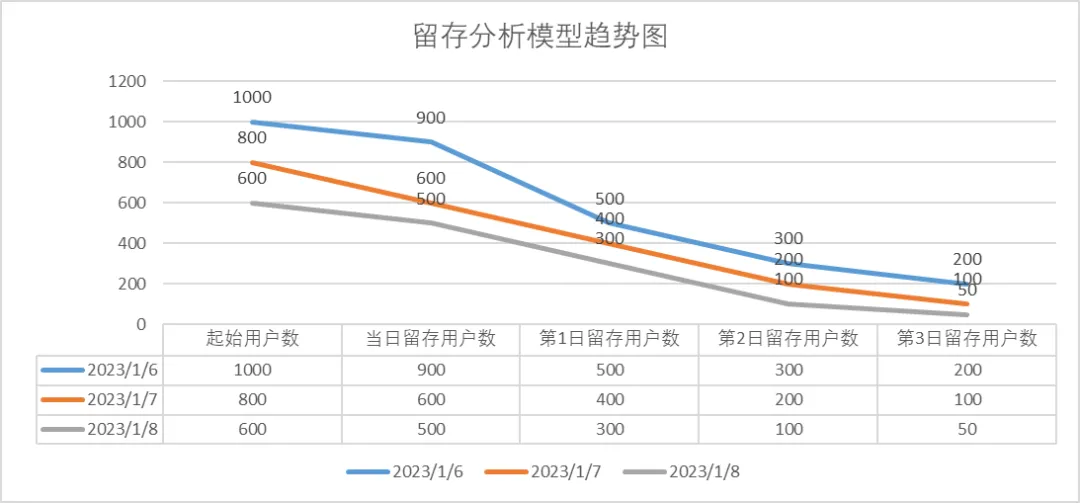
图2:触发起始事件、回访事件对应3日内的留存用户趋势图
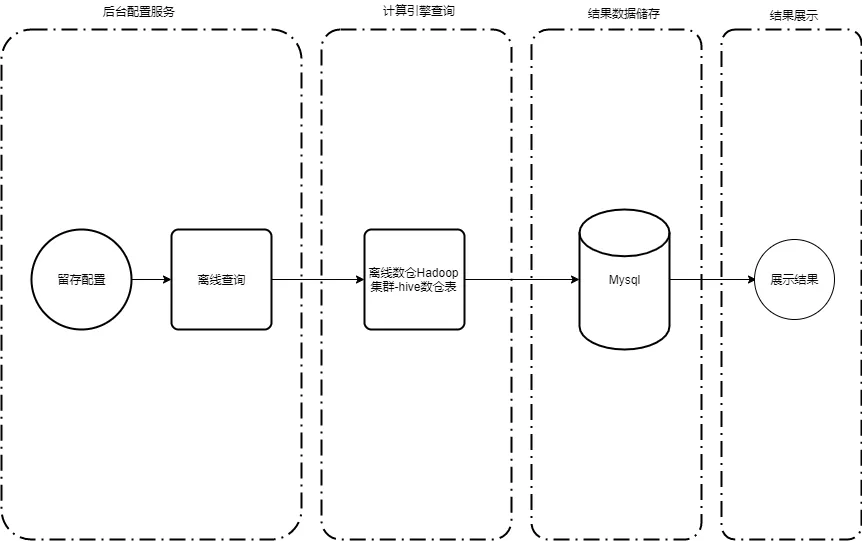
图3 留存分析模型hive架构图
整体架构主要分为配置、计算、存储、展示四阶段。
1. 配置
此阶段主要是工程端的后台服务实现。用户在平台按照自身需求设置起始事件及回访事件、过滤条件、用户群筛选、维度筛选等配置。后台服务收到配置请求后,依据留存分析类型选择不同任务组装器进行sql任务的组装。
2. 计算
平台根据接收到的查询方式,选择离线查询Spark引擎进行分析计算。离线计算结果同步到MySQL。
3. 存储
离线结果集持久化到MySQL数据库中,可通过后台服务展示给用户。
4. 展示
离线结果根据图表配置ID查询MySQL结果表数据进行展示,即时查询通过配置后直接查询展示结果。
离线留存hive执行SQL
select
'起始留存计算日期' as origin_day,
a.day as day,
datediff('起始留存计算日期', a.day) as diff,
count(distinct (a.uid)) as user,
count(distinct (case when b.uid is not null then b.uid end)) as retention
FROM
(
SELECT
day,
uid
FROM
abcd.test
WHERE
day >= if('起始时间' >= date_sub('起始留存计算日期', '留存天数'),'起始时间',date_sub('起始留存计算日期', '留存天数'))
AND day <= if('结束时间' <= '起始留存计算日期','结束时间','起始留存计算日期')
AND event_id = '起始事件')
) a
LEFT JOIN (
SELECT
s.uid
FROM
abcd.test s
WHERE
s.day = '起始留存计算日期'
AND s.event_id = '回访事件'
GROUP BY
s.uid
) b ON
a.uid = b.uid
WHERE
day >= if('起始时间' >= date_sub('起始留存计算日期', '留存天数'),'起始时间',date_sub('起始留存计算日期', '留存天数'))
AND day <= if('结束时间' <= '起始留存计算日期','结束时间','起始留存计算日期')
GROUP BY a.daySQL 当中字段含义分别为:
【origin_day】:起始留存计算日期
【day】:最终留存计算日期
【diff】:第几日留存
【user】:起始用户数
【retention】:留存数
以上SQL含义:查询起始留存计算日期分别到起始时间、结束时间这个区间段中的每天的详细留存数据,不可一次性计算出时间区间内完整的留存数据,需经过多天累计查询,且此SQL执行的结果在留存结果表中展示样例为倒三角填充。
例如:我们定了起始事件和回访事件后,去计算2022-05-01~2022-05-05的每一天的3日留存,此时,起始时间是2022-05-01,结束2022-05-05,留存天数3天。
针对此案例,起始留存计算日期开始日期应该为2022-05-01~2022-05-08,才能计算出2022-05-01~2022-05-05的每一天的3日留存。
第一步 :计算起始留存日期 = 2022-05-01时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,从时间上看,该起始留存计算日期只能计算出2022-05-01日当日留存,执行后结果如下(表3):

表3 起始留存计算日期2022-05-01在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表4):
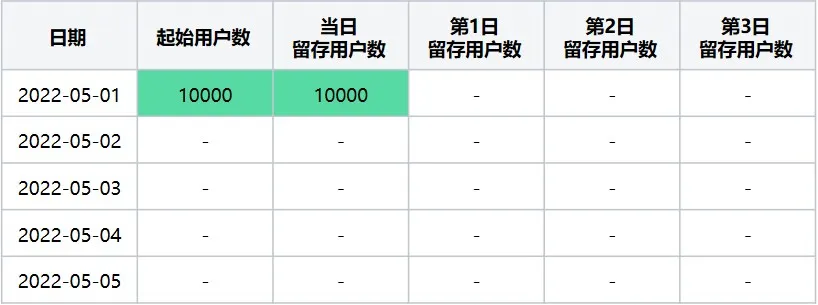
表4 起始留存计算日期2022-05-01在2022-05-01~2022-05-05区间内转换后留存数据表
第二步 :计算起始留存日期 = 2022-05-02时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-01日的第1日留存用户数及2022-05-02日当日留存用户数据,执行后结果如下(表5):

表5 起始留存计算日期2022-05-02在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表6):
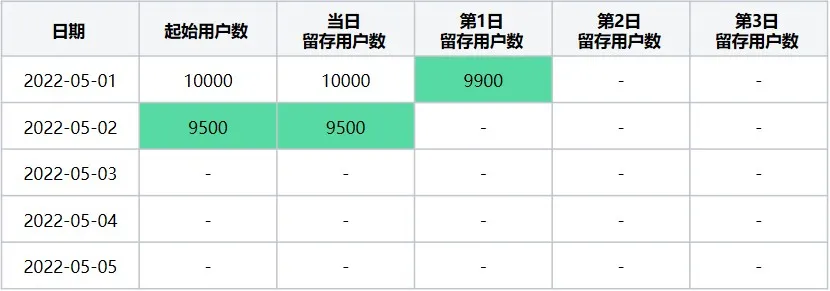
表6 起始留存计算日期2022-05-02在2022-05-01~2022-05-05区间内转换后留存数据表
第三步 :计算起始留存日期 = 2022-05-03时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-01日的第2日留存用户数、2022-05-02日第1日留存用户数据、2022-05-03日当日留存用户数据,执行后结果如下(表7):
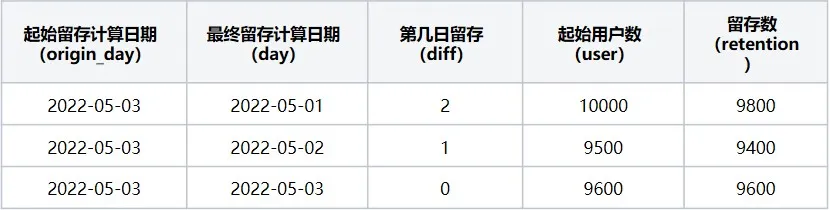
表7 起始留存计算日期2022-05-03在2022-05-01~2022-05-05区间内留存详情数据
此时转换后留存数据表格为(表8):
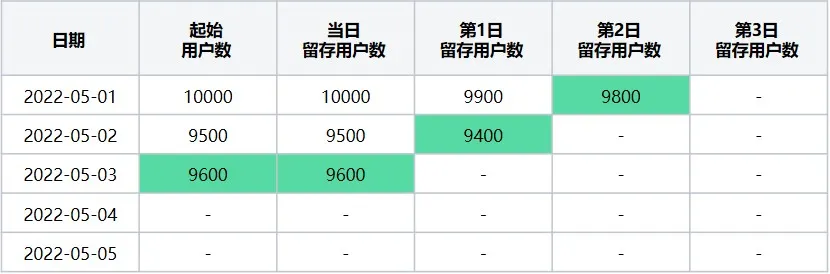
表8 起始留存计算日期2022-05-03在2022-05-01~2022-05-05区间内转换后留存数据表
第四步 :以此类推,计算起始留存日期 = 2022-05-08时,最终留存计算日期区间2022-05-01~2022-05-05日每天的留存数据,该起始留存计算日期可计算2022-05-05日的第3日留存用户数,执行后结果如下(表9):

表9 起始留存计算日期2022-05-08在2022-05-01~2022-05-05区间内留存详情数据
最终数据展示完全后会是一个完整的表格(可得如下结果表10):
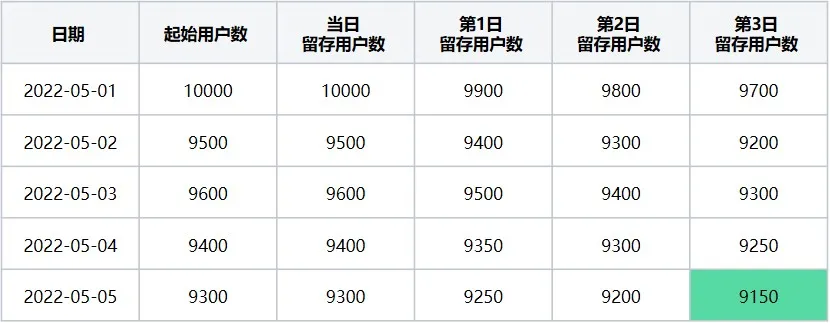
表10 2022-05-01~2022-05-05的每一天的3日留存数据表
存在的问题:
用户在平台上进行报表创建后,在产出报表结果上耗时较长;当配置报表查询周期长,数据量大的情况下,存在计算资源消耗过大的情况。
优化方向:
为了优化报表生成过程,可以考虑使用ClickHouse来处理数据。ClickHouse是一个高性能、分布式、列式存储的数据库系统,特别适合处理大规模数据和复杂查询。
具体而言,可以采用以下ClickHouse 特性 :
将数据导入ClickHouse中,以便更快地查询和计算。ClickHouse支持高效的数据导入和压缩方式,可以大大减少数据的存储空间和查询时间。
利用ClickHouse的列式存储和分布式计算能力,实现增量计算和数据预处理。通过使用ClickHouse的分布式计算能力,可以将计算任务分配给多个节点并行处理,从而加快计算速度。同时,通过使用ClickHouse的列式存储能力,可以避免不必要的数据读取和计算,提高计算效率。
利用ClickHouse的缓存机制,提高查询效率。ClickHouse支持高效的缓存机制,可以将查询结果缓存在内存中,以便更快地响应查询请求。
利用ClickHouse的SQL查询语言,实现灵活的数据分析和报表生成。ClickHouse支持SQL查询语言,可以方便地进行数据分析和报表生成,同时也支持复杂查询和聚合操作,可以满足各种数据分析需求。
通过利用ClickHouse上述特性,进一步提高整个数据分析过程的效率和准确性。
利用ClickHouse进行实时留存查询
传统的离线留存计算通常需要借助Hadoop、Spark等大数据处理框架,需要消耗大量计算资源和时间。而利用ClickHouse进行离线留存计算,可以大大提高计算速度和效率,可以实现秒级响应和高并发查询。
具体步骤如下:
将用户行为数据导入ClickHouse;
根据查询配置数据组装留存SQL用于查询;
利用ClickHouse的高速查询功能,实时查询留存率数据。
利用ClickHouse进行留存图表的产出
利用ClickHouse进行留存计算和查询后,可以通过数据可视化工具对留存数据进行图表化展示,从而更加直观地了解用户留存情况。例如:
利用数据可视化工具连接ClickHouse数据库,查看留存率数据或者通过http请求查询结果表数据;
通过数据可视化工具绘制留存图表,并进行定制化设计和样式调整。
结合hive、ClickHouse两者优点,可将架构做如下优化,对于历史较长时间日期的结果回溯进行hive查询处理,可在ClickHouse中存储的数据作为每天例行查询存储结果。
例行 :是指创建一次图表每日例行执行报表任务,产出数据(例行可回溯ClickHouse中存储日期的留存数据)。
手动 :是指在指定时间范围内执行,执行完成产出任务停止。
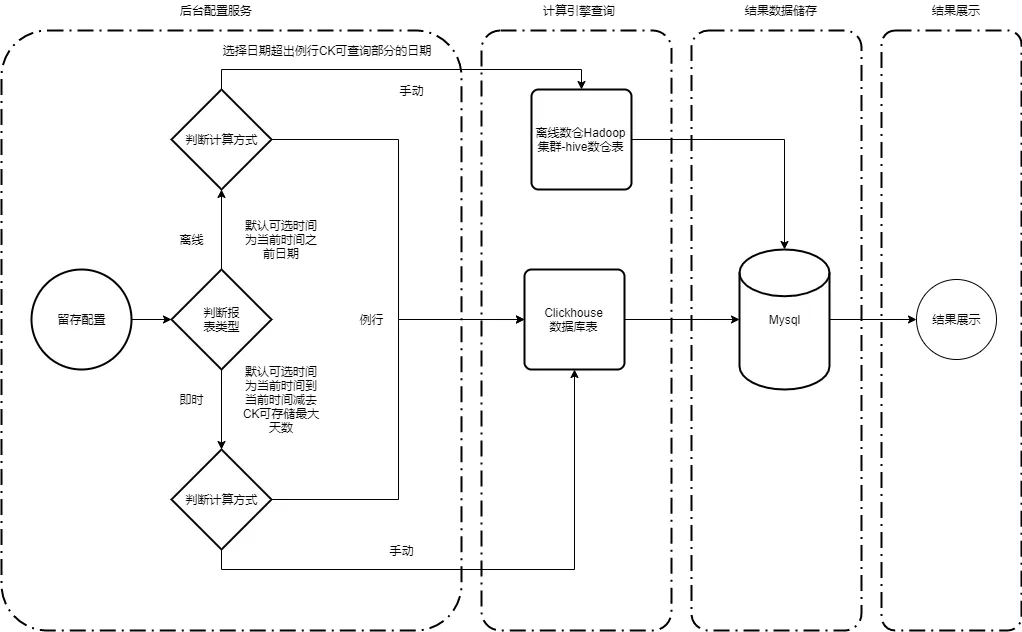
图4 结合ClickHouse、hive后留存分析模型架构图
Retention
该函数将一组条件作为参数,类型为1到32个 UInt8 类型的参数,用来表示事件是否满足特定条件。任何条件都可以指定为参数(如 WHERE)。
除了第一个以外,条件成对适用:如果第一个和第二个是真的,第二个结果将是真的,如果第一个和第三个是真的,第三个结果将是真的,等等。
① 语法
retention(cond1, cond2, ..., cond32);
② 参数
cond — 返回 UInt8 结果(1或0)的表达式。
③ 返回值
数组为1或0。
1 — 条件满足。
0 — 条件不满足。
④ 类型
UInt8
ClickHouse查询SQL
ClickHouse即时查询留存SQL
SELECT retention_date,
USER,
IF(DATEDIFF('day', retention_date, NOW()) >= 1, retain0, NULL) AS retain0,
IF(DATEDIFF('day', retention_date, NOW()) >= 2, retain1, NULL) AS retain1,
IF(DATEDIFF('day', retention_date, NOW()) >= 3, retain2, NULL) AS retain2,
IF(DATEDIFF('day', retention_date, NOW()) >= 4, retain3, NULL) AS retain3
CONCAT(toString(ROUND(retain0 / USER * 100, 4)), '%') AS ratio0,
CONCAT(toString(ROUND(retain1 / retain0 * 100, 4)), '%') AS ratio1,
CONCAT(toString(ROUND(retain2 / retain0 * 100, 4)), '%') AS ratio2,
CONCAT(toString(ROUND(retain3 / retain0 * 100, 4)), '%') AS ratio3
FROM (SELECT b.retention_date,
COUNT(DISTINCT (uid)) AS USER,
SUM(ret[1]) AS retain0,
SUM(ret[2]) AS retain1,
SUM(ret[3]) AS retain2,
SUM(ret[4]) AS retain3
FROM (
SELECT j.retention_date,
uid,
retention(
j.day = j.retention_date,
j.day = j.retention_date + INTERVAL 1 DAY,
j.day = j.retention_date + INTERVAL 2 DAY,
j.day = j.retention_date + INTERVAL 3 DAY,
j.day = j.retention_date + INTERVAL 4 DAY
) AS ret
FROM (SELECT b.day AS retention_date,
b.uid,
t.day AS DAY
FROM (SELECT DAY, uid
FROM abcd.test2
WHERE DAY >= '开始时间'
AND DAY <= '结束时间'
AND event_id IN ('起始事件')
GROUP BY DAY, uid ) b
LEFT JOIN
(SELECT uid , DAY, event_id
FROM abcd.test2
WHERE DAY >= '开始时间'
AND DAY <= '结束时间'
AND event_id IN ('回访事件')
GROUP BY DAY, uid, event_id) t ON b.uid = t.uid
) j
GROUP BY j.retention_date, j.uid ) b
GROUP BY b.retention_date)SQL 当中返回结果含义分别为:
retention_date:留存日期
user:起始用户数
retain0:当日留存用户数
retain1:第1日留存用户数
retain2:第2日留存用户数
retain3:第3日留存用户数
ratio0:当日留存率
ratio1:第1日留存率
ratio2:第2日留存率
ratio3:第3日留存率
以上SQL含义:计算出指定时间区间内3日留存信息,可一次性查询出指定区间内的所有3日留存数据,一个sql即可查询完全。
例如:我们定了起始事件和回访事件后,去计算2022-06-01~2022-06-04的每一天的3日留存,此时,起始时间是2022-06-01,结束2022-06-04,留存天数3天。
针对此案例,在不同的日期查询数据完整性不一致,我们拿2022-06-04日和2022-06-07日两日查询举例。
第一步 :针对2022-06-04日进行计算2022-06-01~2022-06-04的每一天的3日留存,执行后留存数据展示结果如下(表11)。

表11 2022-06-04日计算2022-06-01~2022-06-04的每一天的3日留存数据表
第二步 :针对2022-06-07日进行计算2022-06-01~2022-06-04的每一天的3日留存,执行后留存数据展示结果如下(表12)。

表12 2022-06-08日计算2022-06-01~2022-06-04的每一天的3日留存数据表
趋势结果展示(图5):
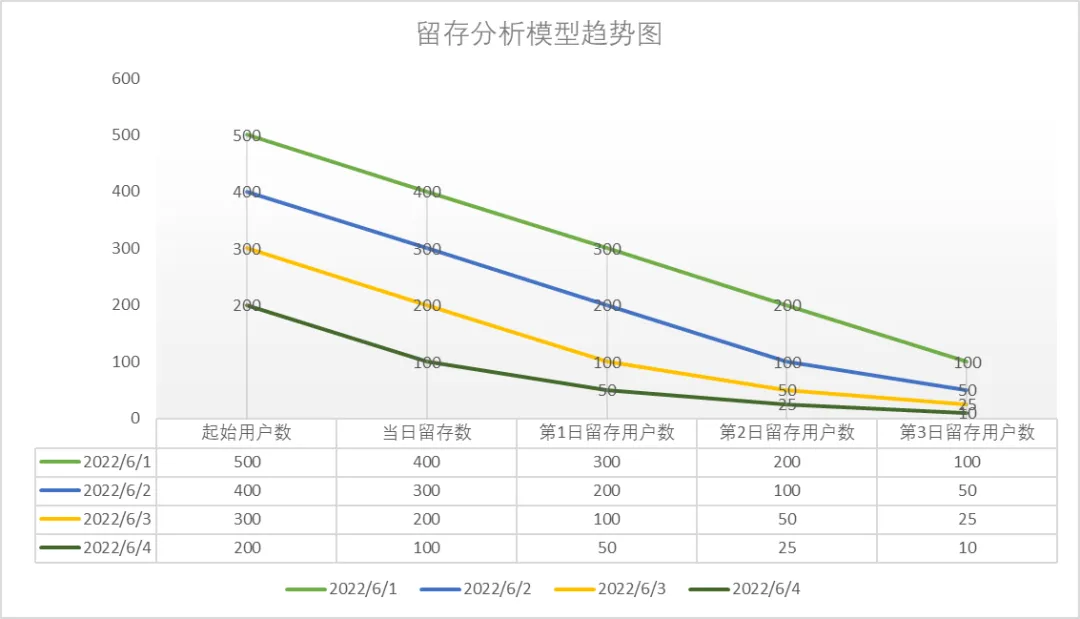
图5 留存分析模型趋势图
本文介绍的留存模型就是数据分析工具箱的核心分析模型,使用的范围十分广泛。它通过计算用户在一段时间内的留存率,可以评估产品、服务或应用程序的用户体验和吸引力,提高用户留存率和活跃度。在实际的生产中,业务可根据自身具体需求和用户特征进行定制化设计,同时也可将通过留存分析得到的人群信息结合其他的数据分析方法进一步的深入分析。例如,从留存中得到的用户人群信息,我们可以进一步的使用路径分析的分析方法,分析用户的访问行为对于产品的影响。
数据分析的工具方法有很多,除了上面提到过得用于分析用户在应用上的访问行为的用户路径分析;也有衡量业务中关键事件之间转化效果的漏斗分析;还有事件分析、归因分析等等,他们共同组成的强大的数据分析工具箱,可以较为全面的分析用户行为的潜在特征与规律,帮助产品或者决策者作为更加可靠的决策。
————————————————————————————————————
更多相关文章:
用户行为分析模型实践(一)—— 路径分析模型
用户行为分析模型实践(二)—— 漏斗分析模型
用户行为分析模型实践(三)——H5通用分析模型
热门资讯
















